News
[2024/09/11] The accepted papers are now available on OpenReview.
[2024/09/07] Slides of the workshop are available.
[2024/07/30] The paper submission deadline has been extended to Aug 09 2024 11:59PM UTC-0.
[2024/07/29] We are excited to announce the winners of the Meta CRAG Challenge 2024.
[2024/06/13] The CRAG paper has been featured by Hugging Face Daily Papers and covered by several media outlets (1, 2, 3).
💬 Introduction
How often do you encounter hallucinated responses from LLM-based AI agents? How can we make LLMs trustworthy in providing accurate information? Despite the advancements of LLMs, the issue of hallucination persists as a significant challenge; that is, LLMs may generate answers that lack factual accuracy or grounding. Studies have shown that GPT-4's accuracy in answering questions referring to slow-changing or fast-changing facts is below 15% [1]; even for stable (never-changing) facts, GPT-4's accuracy in answering questions referring to torso-to-tail (less popular) entities is below 35% [2].
Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate LLM’s deficiency in lack of knowledge and attracted a lot of attention from both academia research and industry. Given a question, a RAG system searches external sources to retrieve relevant information, and then provides grounded answers; see figure below for an illustration.
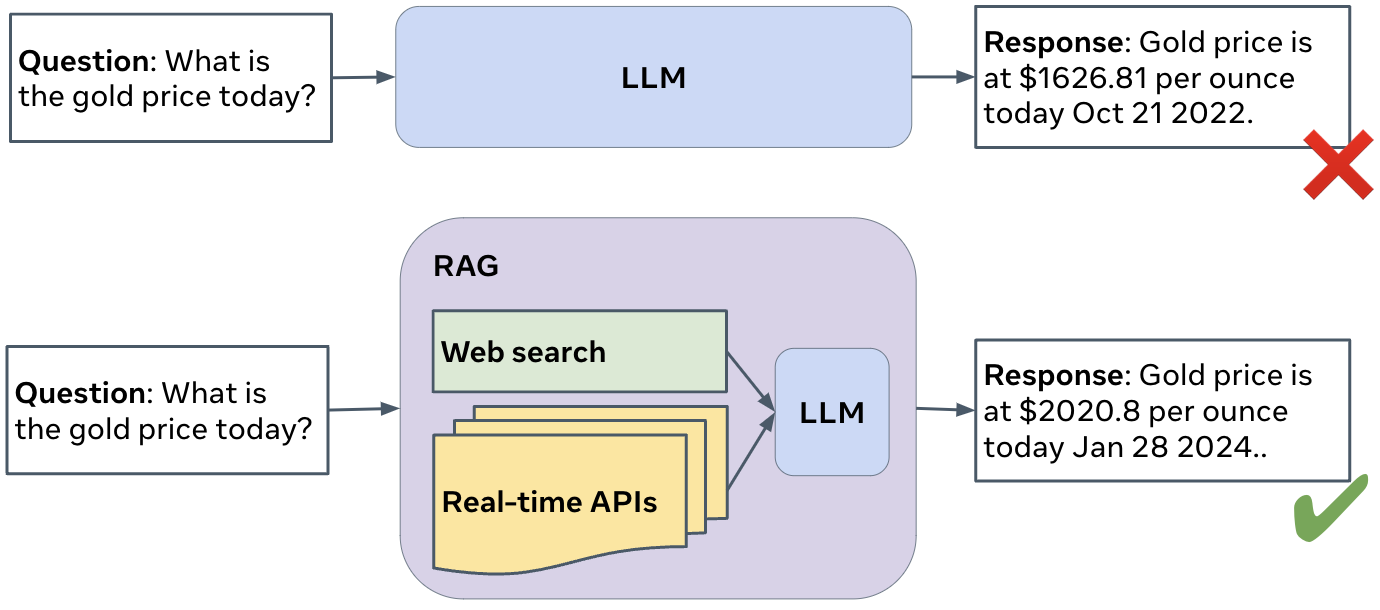
Despite its potential, RAG still faces many challenges, like selecting the most relevant information to ground the answer, reducing question answering latency, and synthesizing information to answer complex questions, urging research and development in this domain. The Meta Comprehensive RAG Challenge (CRAG) aims to provide a good benchmark with clear metrics and evaluation protocols, to enable rigorous assessment of the RAG systems, drive innovations, and advance the solutions.
💻 What is Comprehensive RAG (CRAG) Benchmark? The Comprehensive RAG (CRAG) Benchmark evaluates RAG systems across five domains and eight question types, and provides a practical set-up to evaluate RAG systems. In particular, CRAG includes questions with answers that change from over seconds to over years; it considers entity popularity and covers not only head, but also torso and tail facts; it contains simple-fact questions as well as 7 types of complex questions such as comparison, aggregation and set questions to test the reasoning and synthesis capabilities of RAG solutions.
💻 META Comprehensive RAG Challenge
A RAG QA system takes a question Q as input and outputs an answer A; the answer is generated by LLMs according to information retrieved from external sources, or directly from the knowledge internalized in the model. The answer should provide useful information to answer the question, without adding any hallucination or harmful content such as profanity.
🏹 Challenge Tasks
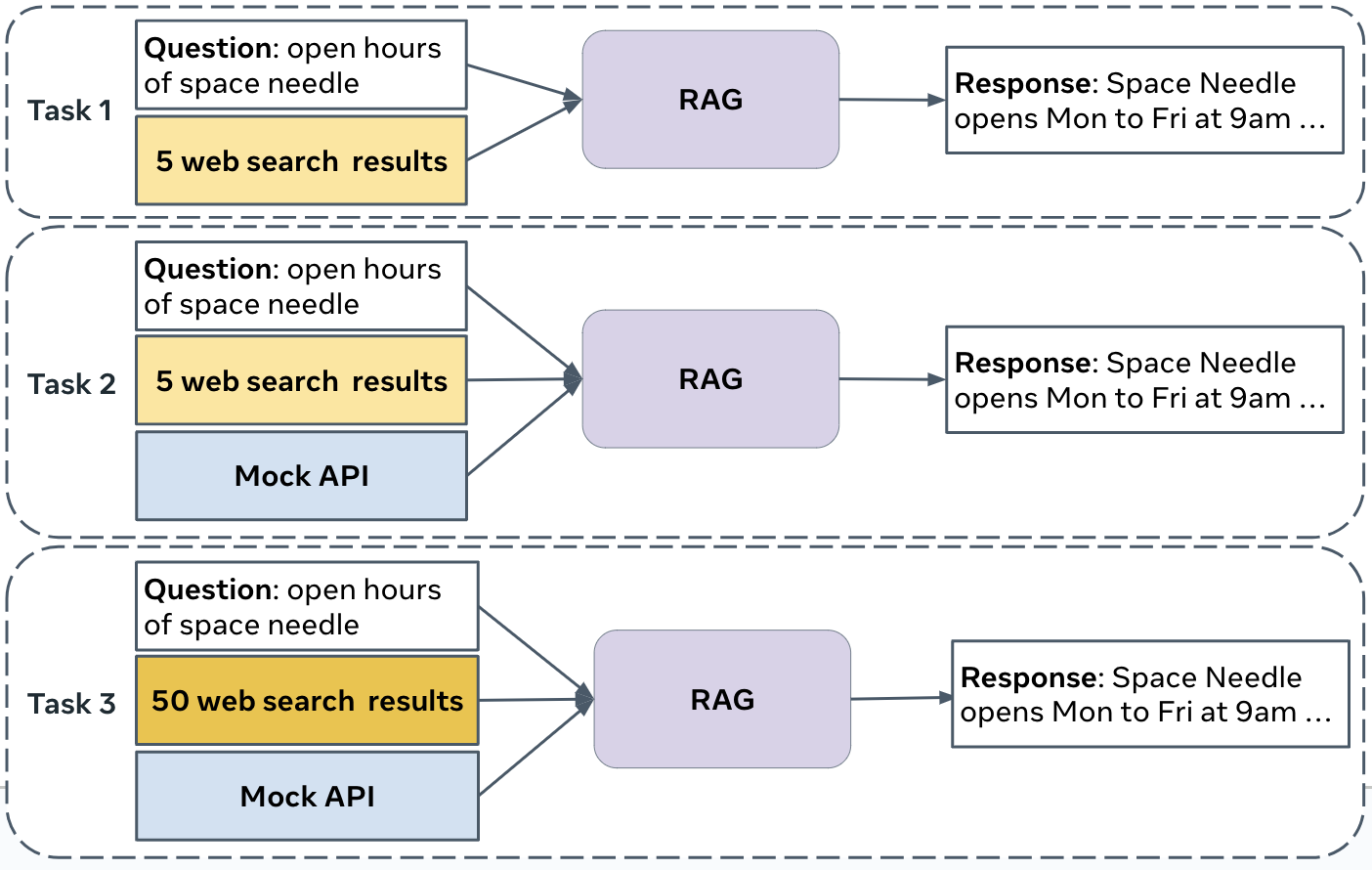
This challenge comprises of three tasks designed to improve question-answering (QA) systems.
TASK #1: WEB-BASED RETRIEVAL SUMMARIZATION Participants receive 5 web pages per question, potentially containing relevant information. The objective is to measure the systems' capability to identify and condense this information into accurate answers.
TASK #2: KNOWLEDGE GRAPH AND WEB AUGMENTATION This task introduces mock APIs to access information from underlying mock Knowledge Graphs (KGs), with structured data possibly related to the questions. Participants use mock APIs, inputting parameters derived from the questions, to retrieve relevant data for answer formulation. The evaluation focuses on the systems' ability to query structured data and integrate information from various sources into comprehensive answers.
TASK #3: END-TO-END RAG The third task increases complexity by providing 50 web pages and mock API access for each question, encountering both relevant information and noises. It assesses the systems' skill in selecting the most important data from a larger set, reflecting the challenges of real-world information retrieval and integration.
Each task builds upon the previous, steering participants toward developing sophisticated end-to-end RAG systems. This challenge showcases the potential of RAG technology in navigating and making sense of extensive information repositories, setting the stage for future AI research and development breakthroughs.
💯 Evaluation Metrics
RAG systems are evaluated using a scoring method that measures response quality to questions in the evaluation set. Responses are rated as perfect, acceptable, missing, or incorrect:
- Perfect: The response correctly answers the user question and contains no hallucinated content.
- Acceptable: The response provides a useful answer to the user question, but may contain minor errors that do not harm the usefulness of the answer.
- Missing: The answer does not provide the requested information. Such as “I don’t know”, “I’m sorry I can’t find ...” or similar sentences without providing a concrete answer to the question.
- Incorrect: The response provides wrong or irrelevant information to answer the user question
Scores are given as follows: perfect = 1 points, acceptable = 0.5 point, missing = 0 points, and incorrect = -1 point. The overall score is a macro-average across all domains, with questions weighted based on type popularity and entity popularity (weights will not be disclosed).
🖊 Evaluation Techniques
This challenge employs both automated (auto-eval) and human (human-eval) evaluations. Auto-eval selects the top ten teams, while human-eval decides the top three for each task.
-
Automatic Evaluation: Automatic evaluation employs rule-based matching and GPT-4 assessment to check answer correctness. It will assign three scores: correct (1 point), missing (0 points), and incorrect (-1 point).
-
Human Evaluation: Human annotators will decide the rating of each response as Perfect, Acceptable, Missing, Incorrect. In addition, human evaluator will require basic fluency for an answer to be considered Perfect.
📙 Evaluation Details
- Every query is associated with a query_time (when the query was made), the query_time may affect the answers, in particular for dynamic questions.
- All False Premise questions should be answered with a standard response “invalid question”.
- All Missing answers should be using a standard response “I don't know.”.
- The ground truth is the answer that was correct at the point when the question was posed and data were collected.
📊 CRAG Dataset Description
📝 Question Answer Pairs
CRAG includes question-answer pairs that mirror real scenarios. It covers five domains: Finance, Sports, Music, Movies, and Encyclopedia Open domain. These domains represent the spectrum of information change rates—rapid (Finance and Sports), gradual (Music and Movies), and stable (Open domain).
CRAG includes eight types of questions in English:
- Simple question: Questions asking for simple facts, such as the birth date of a person and the authors of a book.
- Simple question with some condition: Questions asking for simple facts with some given conditions, such as stock price on a certain date and a director's recent movies in a certain genre.
- Set question Questions that expect a set of entities or objects as the answer. An example is what are the continents in the southern hemisphere?
- Comparison question: Questions that may compare two entities, such as who started performing earlier, Adele or Ed Sheeran?
- Aggregation question: Questions that may need aggregation of retrieval results to answer, for example, how many Oscar awards did Meryl Streep win?
- Multi-hop questions: Questions that may require chaining multiple pieces of information to compose the answer, such as who acted in Ang Lee's latest movie?
- Post-processing question: Questions that need reasoning or processing of the retrieved information to obtain the answer, for instance, How many days did Thurgood Marshall serve as a Supreme Court justice?
- False Premise question: Questions that have a false preposition or assumption; for example, What's the name of Taylor Swift's rap album before she transitioned to pop? (Taylor Swift didn't release any rap album.)
📁 Retrieval Contents
The dataset includes web search results and mock KGs to mimic real-world RAG retrieval sources. Web search contents were created by storing up to 50 pages from search queries related to each question. Mock KGs were created using the data behind the questions, supplemented with "hard negative" data to simulate a more challenging retrieval environment. Mock APIs facilitate structured searches within these KGs, and we provide the same API for all five domains to simulate Knowledge Graph access.
🔑 Baseline implementation
We provide users with three baseline models to help get started. Detailed implementations of these baseline models are accessible through the links provided below. Please refer to this page for steps to download (and check in) the models weights required for the baseline models, and refer to the inline documentation for implementation guide and further details.
⛰ What Makes CRAG Standout?
- Realism: First and foremost, a good benchmark shall best reflect real use cases. In other words, a solution that achieves high metrics in the benchmark shall also perform very well in real scenarios. CRAG query construction considers smart assistants use cases and are realistic; weighting are applied according to the complexity type and entity popularity, such that the metrics can well reflect how we satisfy real user needs.
- Richness: A good benchmark shall contain a diverse set of instance types, covering both common use cases, and some complex and advanced use cases, to reveal possible limitations of existing solutions at various aspects. CRAG covers five domains, consider facts of different timeliness (real-time, fast changing, slow-changing, stable) and different popularities (head, torso, tail), and contains questions of different complexities (from simple facts to requiring reasoning).
- Reliability: A good benchmark shall allow reliable assessment of metrics. CRAG has manually verified ground truths; the metrics are carefully designed to distinguish correct, incorrect, and missing answers; automatic evaluation mechanisms are designed and provided; the number of instances allows for statistical significant metrics, and tasks are carefully designed to test out different key technical components of the solutions.
- Accessibility: CRAG provides not only the problem set and ground truths, but also the mock data sources for retrieval to ensure fair comparisons.
🗂️ Related Work

References
[1] Tu Vu et al., "FreshLLMs: Refreshing Large Language Models with search engine augmentation", arXiv, 10/2023. Available at: https://arxiv.org/abs/2310.03214
[2] Kai Sun et al., "Head-to-Tail: How Knowledgeable are Large Language Models (LLMs)? A.K.A. Will LLMs Replace Knowledge Graphs?", NAACL, 2024. Available at: https://arxiv.org/abs/2308.10168
[3] Ricardo Usbeck et al., "QALD-10–The 10th challenge on question answering over linked data", Semantic Web Preprint (2023), 1–15. Available at: https://www.semantic-web-journal.net/content/qald-10-%E2%80%94-10th-challenge-question-answering-over-linked-data
[4] Payal Bajaj et al., "Ms marco: A human-generated machine reading comprehension dataset", (2016). Available at: https://arxiv.org/abs/1611.09268
[5] Tom Kwiatkowski et al., "Natural questions: a benchmark for question answering research", Transactions of the Association for Computational Linguistics 7 (2019), 453–466. Available at: https://aclanthology.org/Q19-1026/
[6] Jiawei Chen et al., "Benchmarking large language models in retrieval-augmented generation", arXiv preprint arXiv:2309.01431 (2023). Available at: https://arxiv.org/abs/2309.01431